MCP vs RAG: How to Choose the Right AI Architecture
- What Is MCP?
- What Is RAG?
- Typical Components and How They Work?
- 1. How MCP Works – Core Components Explained
- 2. How RAG Works – Core Components Explained
- Use Cases of MCP and RAG
- MCP Use Cases
- RAG Use Cases
- MCP vs RAG: Side-by-Side Overview
- RAG vs MCP: Key Differences
- 1. Data Access Method
- 2. Setup & Maintenance Complexity
- 3. LLM Role
- 4. Security & Compliance Considerations
- 5. Strengths and Limitations
- When to Choose MCP?
- When to Choose RAG?
- Choosing the Right Path in the RAG vs MCP Debate
- Frequently Asked Questions
AI is evolving with each passing year. AI systems are not limited to answering questions; they can help with booking appointments, crunching live data, updating records, sending emails, and even making crucial decisions on the go. Behind this success, two popular architectures are sparking a new debate: MCP vs RAG. These are not common words; they have become integral parts of the AI ecosystem.
From small-scale startups to SMEs to enterprises to Fortune 500 companies, everyone has started using Model Context Protocol (MCP) to ensure models work efficiently in live systems and Retrieval-Augmented Generation (RAG) to ground outputs in massive knowledge bases. If you are keen to invest in AI development services sooner or later, you should be aware of the difference between MCP and RAG, as this will affect scalability, cost, and long-term success.
In this blog, we will discuss the basics of RAG vs. MCP, explain the architecture and workflow, and discuss real-world use cases. We will also compare the two side-by-side to help you quickly decide whether MCP, RAG, or both is best for your project.
What Is MCP?
Model Context Protocol is an open standard framework that enables LLMs to flawlessly find live, structured, and sensitive data without needing it to be pre-embedded or stored in a vector database. Rather than fetching context from static documents, LLMs use external tools, APIs, data sources, databases, or SaaS services in real time to find new and relevant information.
MCP is built primarily to streamline the way large language models interact with the systems. Rather than using separate connectors for every model tool connection, MCP has a standardized framework that all parties can access.
By offering a common layer for instant data access and tool execution, MCP makes it simple to build AI agents that don’t just fetch live information but even follow approved actions, such as updating database records or sending emails.
Meanwhile, MCP overcomes the “M-by-N” integration problem, where every new model and every new service would instead need a custom connection, significantly decreasing complexity and maintenance overhead.
What Is RAG?
Retrieval-Augmented Generation (RAG) combines a large language model with a retrieval engine to fetch relevant documents on demand. Instead of relying only on pre-trained knowledge, it searches external sources such as libraries or vector databases. The result is an AI response that is informed, accurate, and contextually specific to each query.
The main purpose of RAG is to ensure that large language models remain accurate, timely, and context-aware. By extracting relevant, verifiable documents at query time, RAG stores the model’s responses on the go and reduces the risks of false answers.
It even offers models for accessing fresh or specialized information for a particular business or industry, such as the latest research, company policy, or proprietary datasets.
Typical Components and How They Work?
Let’s examine the core building blocks of MCP and RAG to understand how each architecture delivers unique capabilities.
1. How MCP Works – Core Components Explained
The model context protocol is designed considering the client-host-server architecture, which streamlines how AI models interact with tools, data, and prompts. Let’s understand the MCP architecture in detail.
MCP Architecture:
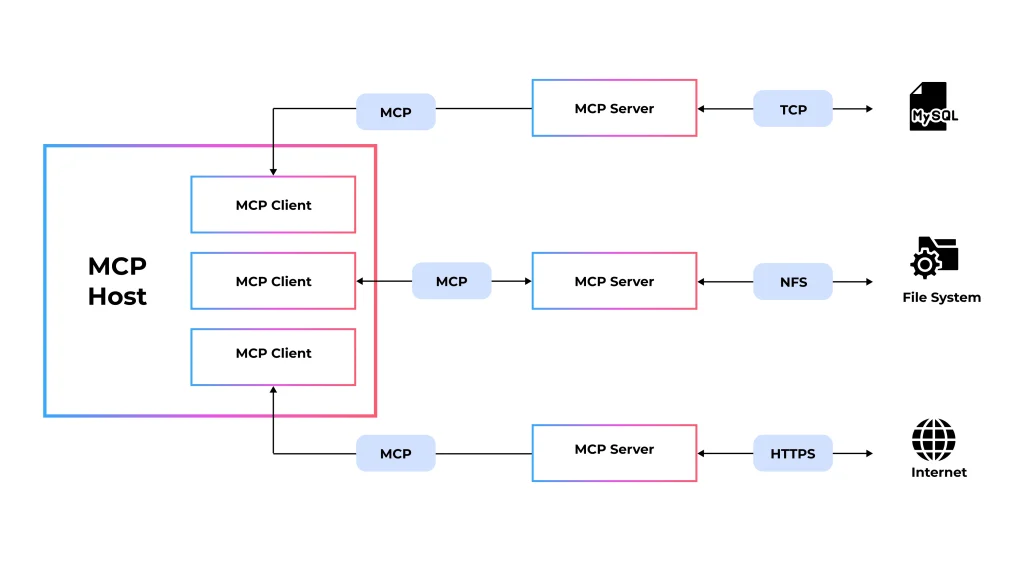
MCP Host: An MCP host reduces the client-server gap. It manages user interactions and permissions and coordinates different requests. It even checks whether the model can efficiently utilize the right tools, prompts, and resources.
MCP Client: An MCP Client runs inside the host application (such as an AI chatbot, IDE, or other productivity tool) and maintains a secure connection to an MCP Server. It manages protocol negotiation, function execution, and message routing, ensuring isolation and safe communication between the host and the server.
MCP Server: An MCP Server exposes specific tools and data, such as files, databases, resources, or prompts, to the Host through the MCP protocol. Each server publishes discovery metadata, executes requested actions, and enforces authentication and permission checks. It can operate locally or remotely and remains isolated from other servers.
Lastly, inside the MCP Server, you’ll still find the discovery layer, authentication controls, and JSON-RPC communication that power the protocol.
In simple terms, it responds to the Host’s requests and returns the final output to the Client.
2. How RAG Works – Core Components Explained
RAG considers a streamlined pipeline that combines document retrieval with language generation, leading to reliable and accurate responses. Let’s examine the RAG architecture closely.
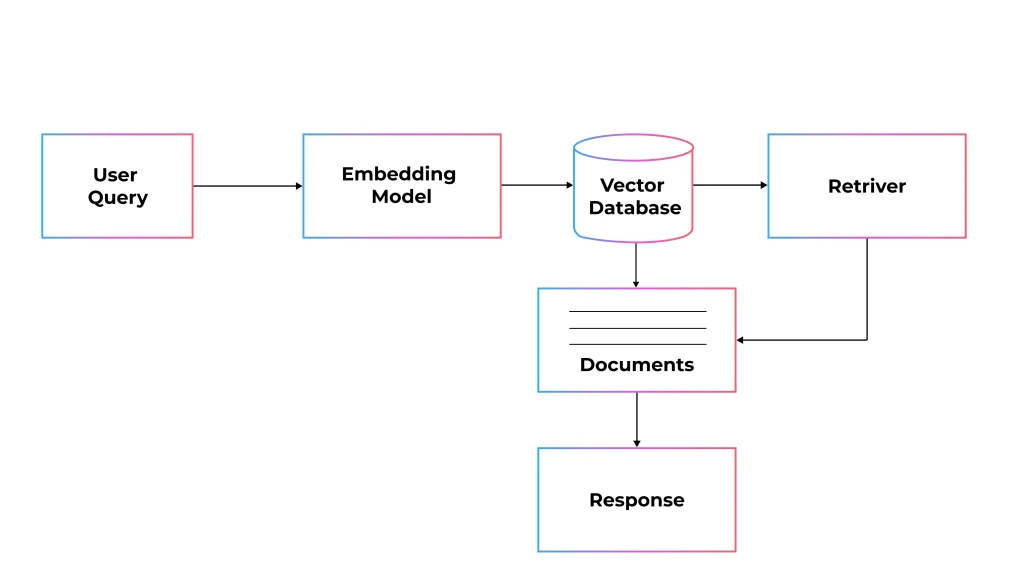
- Embedding Model: This converts the incoming user queries and document chunks into dense vector representations for proficient similarity search. It allows user queries to be matched with an adjustable piece of data in a vectorized form.
- Vector database: The system is designed to store document embeddings in addition to the source text for efficient similarity search. It even enables fast retrieval of required information depending on the query embeddings, such as Pinecone, Milvus, etc.
- Retriever: Considers the vector similarity algorithms or hybrid search to determine the suitable documents or data matches from the vector database. It further filters and ranks the fetched data to select the best context.
- Context Construction: Collects and organizes the retrieved content into a prompt that LLM can understand, considering the formatting or token limits in mind. It builds a highly enhanced prompt for the next step, thus fine-tuning the prompt size and focus.
- LLM Generation: This process merges the user query and retrieved context to produce final, context-aware responses. It considers built-in training knowledge and the latest data to decrease hallucinations and enhance relevance.
Use Cases of MCP and RAG
Now, businesses and developers rely on basic AI prompts and leverage MCP and RAG to provide meaningful automation, data access, and dynamic business impact. Here’s how MCP and RAG can help develop more innovative, reliable, and next-gen AI solutions.
MCP Use Cases
Real-Time Data Access: This method retrieves critical business intelligence information in real time from databases and APIs, enabling fast, confident decisions. For example, LLMs can pull live stock data, IoT sensor feeds, or transaction logs for immediate insights.
Task Automation: Connects LLM with tools like email services, CRMs, or project management applications. By this, MCP allows AI to complete repetitive tasks, such as invoice generation, sending emails, and more, automatically.
Triggering Workflows: Flawlessly connect AI agents with business workflows like HR, finance, etc. This further leads to the launch of complex, multi-step processes, such as onboarding or code deployment, using a single prompt.
Agentic Applications: It powers autonomous AI agents to find, filter, and implement the right tools and integrations whenever required. Thus, it helps build flexible and self-directed systems in changing environments.
RAG Use Cases
Customer Support: Quickly resolve customer queries by validating the model’s response against policy documents, historical tickets, and user manuals; hence, the responses are supported by trusted references, leading to higher customer satisfaction.
Enterprise Search: Employees insert a query to search a massive internal knowledge base comprising thousands of files, records, emails, and more using natural language. They receive accurate, context-rich answers in a few seconds.
Personalized Recommendations: This method combines user data with internal and external sources to recommend the most suitable content, products, or services based on choices and past behavior. Thus, it provides bespoke value and enhances customer engagement.
Document Summarization: Scan a massive collection of reports, contracts, or research papers to extract valuable insights. It then delivers straightforward and trustworthy information to business professionals and helps them make better decisions.

MCP vs RAG: Side-by-Side Overview
MCP and RAG are there to resolve different challenges regarding AI integration. One is responsible for tool-driven actions, while the other provides LLMs with the necessary data. The table below helps you understand key differences between MCP and RAG.
| Factors | MCP | RAG |
| Data Type | Dynamic and structured (APIs, databases, services, and real-time event streams). | Static and unstructured(Textual knowledge bases, vector databases, and document stores). |
| Retrieval or Connection Method | Bi-directional protocol managing direct tool invocation. | Vector similarity search or hybrid retrieval from the indexed data portions. |
| LLM Role | Executes actions and integrates tool responses into workflows using live inputs. | Generates answers enriched with retrieved contextual passages. |
| Setup & Maintenance Complexity | Requires a setup of protocol, authentication, and server integrations. | Needs data chunking, embedding, and vector database management. |
| Execution Flow | Requests are sent from the Client to the server, executed remotely, and fed back to LLM. | The query is embedded, relevant docs are retrieved, context is constructed, and the final output is generated. |
| Impact on Model Input | Minimal; only parameters or small responses pass through prompts. | Significant; retrieved text expands the prompt’s context window. |
| Security | Fine-grained permissions and isolated servers safeguard operations. | Controlled access to documents and encrypted vector databases. |
RAG vs MCP: Key Differences
MCP and RAG are both responsible for expanding the capabilities of large language models; they offer the most suitable solution to the problems in various ways. Understanding the difference in detail helps you choose the right one for specific AI applications.
1. Data Access Method
MCP
MCP offers live, event-driven access to external systems. Following the host-client-server architecture, an LLM can instantly interact with APIs, query databases, or tools in real time. Data flows to and from the MCP server and host application, ensuring low latency and eliminating useless data duplication.
RAG
RAG depends heavily on semantic retrieval from the unstructured or semi-structured document store. Documents are broken into pieces, integrated into vectors, and later stored in a vector database. During executing a query, the model fetches and passes the suitable passages into its propt, ensuring that responses use existing textual knowledge instead of live transactional data.
2. Setup & Maintenance Complexity
MCP
To set up MCP, one needs to configure hosts, clients, and servers, set up authentication, and install a protocol for tool discovery. Once things are installed, they streamline future connections by defining steps for adding new tools. Ongoing maintenance involves updating permissions, ensuring high security, and handling server instances.
RAG
RAG setups require preprocessing documents, dividing large documents into small texts, crafting embeddings, and building and maintaining the entire vector store. Constant updates are required as the content changes; new documents must be embedded and reindexed. Although there is no need for a live protocol, the pipeline requires constant optimization and tracking to ensure retrieval is done accurately whenever needed.
3. LLM Role
MCP
In MCP, the large language model acts as an agent. It interprets user prompts and autonomously controls third-party tools and data sources, sending requests to perform actions or fetch live data. It then returns structured responses to drive downstream workflows.
RAG
In RAG, the model acts as a knowledge-enhanced generator. Instead of relying on external actions, it retrieves textual evidence and generates grounded, coherent responses. The primary purpose of LLM is to combine the query and the retrieved text to deliver reliable and factual output.
4. Security & Compliance Considerations
MCP
MCP puts much effort into fine-grained security and offers in-depth access controls per connection via authentication and audit trails to support enterprise compliance needs. Its real-time interaction mode relies on robust isolation and permission checks.
RAG
RAG emphasizes data governance within the knowledge base. Protecting sensitive document repositories, handling data ingestion pipelines, and encrypting vector databases are necessary. Even though RAG doesn’t offer much granular control over data and is less action-oriented, strict policies must be implemented to prevent the unauthorized retrieval of sensitive information.
5. Strengths and Limitations
| Aspect | MCP | RAG |
| Strengths | Real-time data retrieval and query execution on structured data.Standardized protocol streamlines tool integrationsRobust isolation and granular permission controlsAccurate data retrieval from the most suitable APIs. | Scalable retrieval of unstructured knowledge.Decreases hallucinations and improves factual accuracyEasy to extend with new documents or knowledge bases.Data is stored securely, yet less granular live control. |
| Limitations | Requires host, Client, and server setup. Ongoing authentication and protocol managementMainly valuable when live data or tool control is crucialSecurity layer complexity grows with scale. | Continuous data optimization and re-embedding are needed. Retrieval limited to stored text, not real-time data.Context window can expand quickly, increasing token costs. |
When to Choose MCP?
MCP is the best choice when your AI needs to take action, not just answer, connecting securely to live systems and tools.
- Go with MCP to retrieve live data from market feeds, IoT sensors, or transaction logs for quick, high-stakes decisions.
- Go with MCP to trigger workflows or streamline various task sequences using tools, APIs, or business systems.
- Activate multi-step business processes using a single prompt, such as onboarding, code deployment, or financial approvals.
- Develop autonomous agents that find, filter, and execute the proper set of tools without constant human direction.
- Operate in highly controlled industries, such as finance, healthcare, and compliance, that need strong authentication, traceability, fine-grained permissions, and server-level audit trails.
- Integrate multiple LLMs and tools using a standardized protocol that scales based on system requirements.
When to Choose RAG?
- RAG is best for providing grounded, knowledge-based responses from large or evolving information resources.
- Reduce the hallucinations by preparing answers from verifiable data fetched during the query time.
- Work on tasks that include deep search, summarization, Q&A, or fact-checking from internal or external sources, and choose RAG.
- Deliver customized content or recommendations according to the user context and requirements.
- Fetch necessary data for industries, such as healthcare, finance, or legal, to develop valid answers.
- Supports AI virtual assistants that need live facts, product details, or regulatory updates.
- Build an AI solution that answers the users’ queries by checking growing document bases, such as knowledge bases, wikis, or academic papers.
Choosing the Right Path in the RAG vs MCP Debate
As of now, we have compared MCP vs RAG from various angles, including definitions, key components, use cases, and the most well-known differences. In simple terms, MCP is great when you need agentic, real-time actions and integrations.
In contrast, RAG works well at grounding answers from the massive, evolving knowledge base. When considering RAG vs MCP or vice versa, the right choice depends heavily on whether you want AI to retrieve live data or provide deeply informed responses.
Want to build next-gen AI applications for your business? Openxcell has a team of AI experts who deliver professional LLM development services for startups and enterprises worldwide. Our teams understand your business needs and integrate the right architecture to provide a suitable AI solution.
Frequently Asked Questions
Can MCP and RAG work together?
Definitely, MCP and RAG can work together. MCP can act as a secure bridge to real-time tools and data sources, while RAG is responsible for retrieving up-to-date information from the knowledge base. Together, they allow the LLM to trigger real-time actions and reason over new information in a single workflow, thus enhancing enterprise-grade AI systems.
Which LLMs support MCP?
Any model that can interact easily with MCP is good to go. These include Claude (via Claude Desktop), OpenAI (via the Responses API), and local LLM execution engines like Ollama.
Is MCP a Replacement for Traditional APIs?
Not really. MCP standardizes and secures how LLMs interact with the tools; however, those tools might still expose traditional REST or GraphQL APIs.
How Does RAG Handle Sensitive or Private Data?
RAG can function effectively in private infrastructure using built-in vector databases and encrypted storage. Proper data governance, access controls, anonymization, and encryption are necessary to secure sensitive information.
Is RAG suitable for real-time, dynamic information?
RAG is best for improving factuality using stored or frequently updated material; however, it generally retrieves from pre-indexed material, not live transactional systems. Combine RAG with MCP or specialized APIs for instant retrieval and response for true real-time data or action.


Girish is an engineer at heart and a wordsmith by craft. He believes in the power of well-crafted content that educates, inspires, and empowers action. With his innate passion for technology, he loves simplifying complex concepts into digestible pieces, making the digital world accessible to everyone.




