LLM Security: Protecting AI Models from Attacks & Data Leaks
- What is LLM Security?
- Common Security Risks Associated with LLMs
- OWASP Top 10 Risks for LLMs
- LLM01: Prompt Injection
- LLM02: Data Leakage
- LLM03: Training Data Poisoning
- LLM04: Insecure Plugin Execution
- LLM05: Model Denial of Service (DoS)
- LLM06: Excessive Agency
- LLM07: Supply Chain Vulnerabilities
- LLM08: Overreliance on Model Outputs
- LLM09: Insecure Output Handling
- LLM10: Model Theft
- Case Studies Highlighting LLM Security Vulnerabilities
- 1. Prompt Injection in Top LLM Tools
- 2. Data Leakage in Financial AI Models
- 3. Adversarial Attacks on Healthcare AI
- Best Practices for Securing LLMs
- Top LLM Security Tools & Frameworks for Protection
- Understanding LLM Security: The Future of Safe AI
- Final Words on Securing the Future of AI with LLM Security
Imagine a world where your AI possesses instant access to every book, conversation, and idea ever recorded, an intelligence capable of synthesizing knowledge in seconds. The possibilities seem limitless.
But what happens when this vast knowledge is manipulated, fed false information, or exploited for malicious purposes? This is the challenge of LLM security.
As AI development services push the boundaries of innovation, securing these models to remain trustworthy and resilient is crucial. It’s no longer just about creating powerful AI but securing it. The future of AI depends not only on its intelligence but on our ability to protect it from misuse.
What is LLM Security?
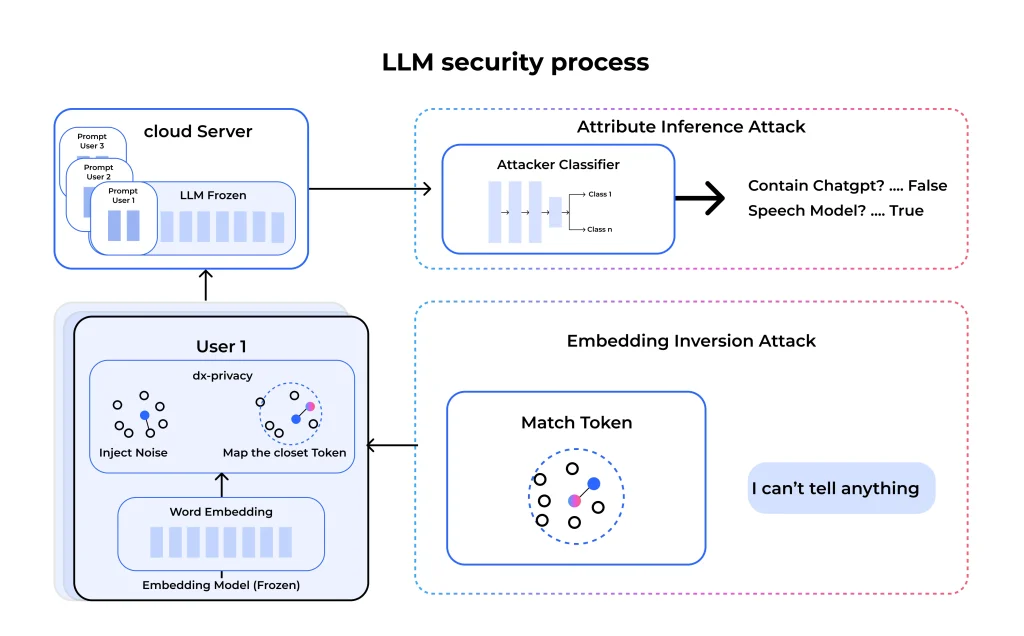
LLM security refers to the measures and strategies used to protect large language models from issues like data breaches, prompt injections, and adversarial attacks. As LLM development advances, security is added to prevent unauthorized access, bias exploitation, and misuse of AI-generated content.
With the increasing integration of LLMs in business operations, safeguarding sensitive data and maintaining model integrity are important. Secure LLMs provide reliable, unbiased, and trustworthy AI interactions. This includes addressing not just traditional vulnerabilities but also the emerging risks tied to non-human identities, such as automated agents or services that access LLMs without human oversight.
Utilizing LLM security tools provides data privacy, prevents manipulation, and ensures compliance with AI regulations. The strong security measures also improve model efficiency, building user trust in AI-driven applications. But before integrating LLM tools, let’s learn about the top common risks for LLMs.
Common Security Risks Associated with LLMs
As businesses integrate the new AI services into their workflows, LLM security becomes an important consideration. Large language models are vulnerable to different threats that can compromise data integrity, model reliability, and user trust. Implementing strong security measures gives a secure LLM, which delivers accurate and safe outputs.
- Prompt Injection Attacks – The attackers easily manipulate inputs to create misleading or harmful responses, leading to security breaches.
- Training Data Poisoning – Malicious data injections during LLM fine-tuning can corrupt the model learning, causing inaccurate or biased outputs.
- Model Theft – Unauthorized access to proprietary LLMs leads to intellectual property theft and competitive risks.
- Insecure Outputs – Unfiltered responses might expose sensitive information or generate inappropriate content.
- Adversarial Attacks – Manipulated input tricks LLMs into misclassification or unintended responses, reducing reliability.
By executing advanced security protocols and using best practices, these risks can be effectively mitigated, giving a secure LLM for safe and reliable AI interactions.
To further strengthen LLM security, it is essential to understand the OWASP Top 10 risks for LLMs, highlighting the most critical exposures and recommended defense strategies.
OWASP Top 10 Risks for LLMs
As large language models become more integrated into business and consumer apps, understanding LLM security risks is necessary. The Open Web Application Security Project (OWASP) has identified the top 10 vulnerabilities affecting LLMs, helping organizations to secure AI deployments against potential threats.
LLM01: Prompt Injection
Attackers manipulate prompts by inserting the hidden instruction to change the model behavior. It can lead to unauthorized actions, misinformation, or system exploitation. Proper input validation and context filtering can help to mitigate the risk.
LLM02: Data Leakage
LLMs are trained on sensitive information, which may unintentionally reveal private data in responses, leading to compliance violations, identity theft, and privacy breaches. Implementing differential privacy techniques and controlled data access can reduce exposure. It’s vital to take control of your personal data trail. A good first step is to use Aura’s free digital footprint checker to see what’s already out there.
LLM03: Training Data Poisoning
If attackers inject biased or harmful data into the training process, the model might give inaccurate or unethical outputs. It gives rigorous dataset curation, and strong LLM security monitoring can prevent manipulation.
LLM04: Insecure Plugin Execution
Many LLMs integrate with third-party apps, which can introduce issues if not properly secured. A compromised plugin may expose sensitive data or execute unauthorized commands. Regular security audits and API access controls are crucial.
LLM05: Model Denial of Service (DoS)
Attackers can overwhelm an LLM with excessive or malformed queries, causing performance degradation and system failure. Tate limiting, anomaly detection, and request filtering can protect against such attacks.
LLM06: Excessive Agency
Relying too much on LLMs for autonomous decision-making without human intervention might lead to severe consequences. It includes regulatory non-compliance, biased outputs, or operational errors. Keeping human oversight in important processes is key.
LLM07: Supply Chain Vulnerabilities
LLMs mostly rely on external datasets, APIs, or model dependencies that may contain security flaws. Threat actors can exploit these weak links to manipulate responses or compromise the system. The vetting of sources and maintaining strict security controls are essential.
LLM08: Overreliance on Model Outputs
Blindly trusting AI-generated content without verification can spread misinformation and lead to poor decision-making. Encouraging human validation and incorporating fact-checking mechanisms help maintain accuracy and reliability.
LLM09: Insecure Output Handling
Poorly sanitized model responses can lead to command injection or cross-site scripting attacks (XSS). Secure coding practices and solid input/output sanitization methods prevent exploitation.
LLM10: Model Theft
Unauthorized access to proprietary LLM architectures or weights can result in intellectual property loss and unauthorized model usage. Using encryption, access control mechanisms, and digital watermarking can protect valuable AI assets.
While LLM security presents challenges, organizations can mitigate risks by implementing stringent security measures, monitoring open issues, and adopting best practices in LLM security development.
A Must Read: SLM vs LLM: Choosing the Right AI Model for Your Business
Case Studies Highlighting LLM Security Vulnerabilities
As the LLM model gains traction, security concerns, such as data leakage, prompt injection, and adversarial attacks, are rising. While LLM security tools help mitigate risks, understanding real-world vulnerabilities is essential.
1. Prompt Injection in Top LLM Tools
Researchers manipulated prompts in top LLM tools, bypassing ethical safeguards to generate restricted content and exposing weak input validation.
2. Data Leakage in Financial AI Models
A fintech LLM unintentionally exposes sensitive user data due to insufficient output filtering, raising concerns about compliance and privacy.
3. Adversarial Attacks on Healthcare AI
An LLM-powered diagnosis tool is tricked into providing incorrect medical advice through adversarial prompts, demonstrating potential harm.
Strong security strategies and proactive threat detection are important to safeguard LLM applications. To address these vulnerabilities, organizations must adopt best practices for securing LLMs to ensure safe and reliable AI deployment.
Best Practices for Securing LLMs
LLM security is indeed important to prevent data leaks, adversarial threats, and unauthorized access. By implementing robust safeguards, organizations can enhance the reliability and safety of language models.
- Data Sanitization and Validation: Filtering and validating input/output data helps to prevent malicious prompt injections and sensitive data exposures.
- Access Controls and Authentication: Restricting model access by role-based permission and multi-factor authentication minimizes unauthorized usage. The addition of API rate limits and encrypted authentication tokens for extra security.
- Regular Security Audits: Periodic reviews identify vulnerabilities and ensure compliance with security standards. Conducting third-party audits can uncover hidden risks and strengthen security frameworks.
- Adversarial Testing: Simulating attacks helps to evaluate models’ resilience against prompt manipulation and bias exploitation. Security teams that want a structured approach to this process should conduct llm penetration testing to systematically probe model boundaries, identify exploitable weaknesses, and document attack paths before threat actors discover them first. Use red teaming techniques to anticipate and mitigate evolving threats.
- Monitoring and Logging: Continuous tracking of interaction supports real-time threat detection and LLM evaluation for security improvements. Applying anomaly detection systems to flag suspicious activity and prevent breaches.
To effectively implement these best practices, organizations need to use these specialized tools and frameworks for LLM to improve protection and mitigate risks.
Top LLM Security Tools & Frameworks for Protection
Implementing strong security measures requires the right LLM security tools and frameworks to find issues, prevent attacks, and ensure compliance. These solutions help safeguard LLMs from data leaks, unauthorized access, and adversarial threats.
- Guardrails AI – It implements content filtering and response validation to prevent prompt injections.
- OpenAI Moderation API – Detects and blocks harmful or biased content in the LLM outputs.
- NeMo Guardrails – This enhances LLM security by enforcing safe interactions and ethical constraints.
- LLM Shield – Provides real-time monitoring and abnormality detection for model responses.
- LangChain Security Modules – Adds authentication and access control to LLM-powered apps.
By integrating these tools, organizations can strengthen their LLM Agents and build resilient AI systems. As LLM threats continue to evolve, the future of LLM security will rely on advanced AI-driven defenses and proactive risk-alleviation strategies.
Understanding LLM Security: The Future of Safe AI
As LLMs change, ensuring their security is paramount. The future of LLM security will focus on strong threat detection, ethical AI governance, and real-time monitoring to prevent misuse.
Advances in adversarial training and differential privacy will enhance resilience against cyber threats. Regulatory frameworks will also play an important role in mitigating LLM security risks. Organizations must adopt proactive security measures to safeguard data integrity and user privacy.
As AI adoption grows, a multi-layered security approach will be essential to ensure responsible and safe AI deployment.
Additional Read: Foundation Model vs LLM: Choosing the Best AI Model
Final Words on Securing the Future of AI with LLM Security
As AI continues to advance, it is essential to ensure that LLM security is no longer optional. From preventing prompt injections to mitigating adversarial threats, organizations must implement strong security measures to protect AI-driven apps.
With the increasing integration of LLMs in various industries, securing these models gives data privacy, ethical AI use, and reliable performance. Businesses must adopt a proactive security framework to prevent exploitation and maintain trust in AI systems.
That’s where our company comes in. At Openxcell, we don’t just secure AI; we revolutionize it. As a leading AI solutions provider, we specialize in cutting-edge AI security while also delivering end-to-end AI development, integration, and optimization services. Our expertise spans from secure model development to continuous monitoring, ensuring your LLM deployments remain resilient, compliant, and risk-free. With Openxcell, businesses gain more than just security; they gain a trusted AI partner committed to driving innovation, scalability, and long-term success.


Manushi, a former literature student, now crafts content as a writer. Her style merges simple yet profound ideas. Intrigued by literature and technology, she strives to produce content that captivates and stimulates.




