Pgvector vs Pinecone: Choosing the Right Vector Database
In the rapidly changing world of machine learning and AI, finding the proper vector database is essential for powering applications. It has many benefits, like semantic search, NLP, and recommendation engines. The one popular fight between database races is Pgvector vs Pinecone, as both databases have unique approaches.
Pgvector interfaces with PostgreSQL, while Pinecone provides a fully managed, high-performance solution. Which one is best for your needs? Let’s keep diving into both of these vector databases.
Pgvector is an extension for PostgreSQL, enabling developers to store and query vector embeddings directly in its database, making it an attractive option for those already using PostgreSQL.
Pinecone, on the other hand, is a dedicated vector database designed for scalability and speed, offering a managed service tailored to high-demand use cases. Now, let’s compare Pinecone vs Pgvector in detail.
What is Pgvector?
In the comparison of Pgvector vs Pinecone, the Pgvector is an open-source extension for PostgreSQL design that stores and queries vector embeddings directly within the database. It is widely used in recommendation engines, NLP, and semantic search applications.

Core Features of Pgvector
- Vector Storage– Store embeddings directly in PostgreSQL.
- Integration – Works natively with PostgreSQL, making it easy for existing users.
- Similarity Search – Provides efficient similarity search capabilities.
- Flexibility – Supports various use cases and data types.
Pros
- Performance – Optimized for vector searches within PostgreSQL.
- Cost-effectiveness – Open source and free, with no extra licensing fees.
- Flexibility – Adapts to multiple machine learning and analytics use cases.
Cons
- Scalability – It has limitations for large scales compared to dedicated vector databases.
- Complexity – Requires PostgreSQL expertise for effective setup and performance tuning.
What is Pinecone?
When it comes to vector database comparison, Pinecone is a fully managed vector database specially designed for scalable similarity search on high dimensional data, like embedding from machine learning models.
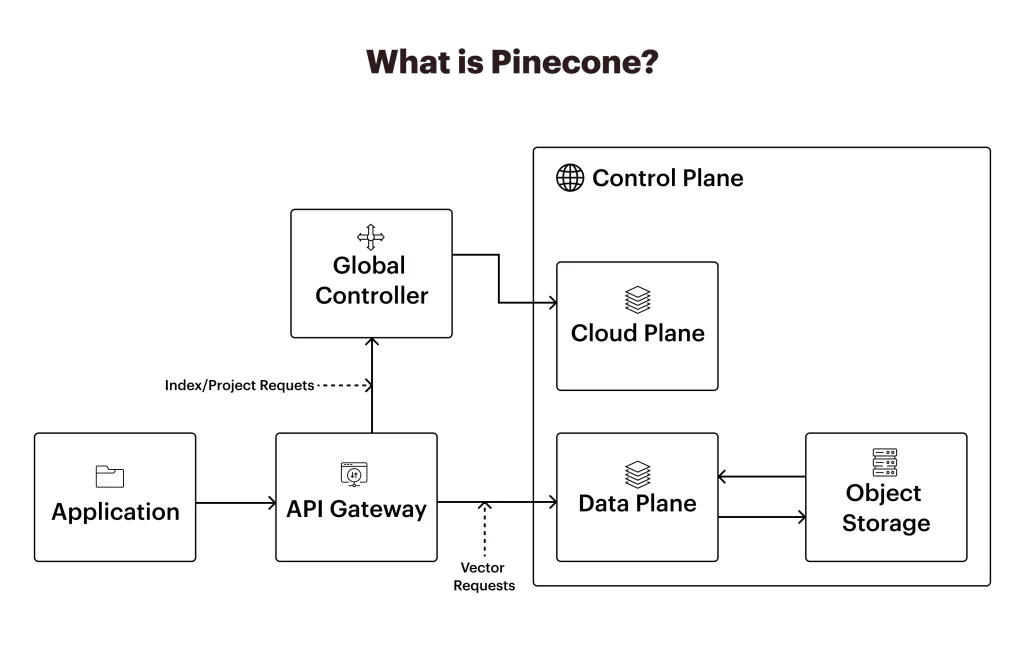
Core Features of Pinecone
- High-Speed Vector Search – Optimized for rapid, large-scale similarity searches.
- Scalability – Easily handles large datasets with minimal configuration.
- Managed Service – Fully managed infrastructure, reducing operational overhead.
- APIs and Integration – Simple APIs for easy integration with analytics workflows and ML.
Pros
- Scalability – Designed to handle large volumes of data effortlessly.
- Ease of Use – Intuitive setup management with minimal maintenance.
- Managed Service – Offloads infrastructure management to Pinecone.
Cons
- Cost – Higher pricing due to the managed service model.
- Vendor Lock-in – Dependency on Pinecone’s platform and infrastructure.
Key Features Comparison : Pgvector vs Pinecone
Here’s a comparison table for Pgvector vs Pinecone focusing on ease of use, scalability, integration, and other essential features:
| Features | Pgvector | Pinecone |
| Ease of Use | Familiar with PostgreSQL, requires SQL knowledge to work with vectors | User-friendly with intuitive API, database knowledge required |
| Scalability | Suitable for small to medium workloads, scaling on PostgreSQL can be complex and needs tuning | High scalability by design, handles millions of vectors with serverless architecture |
| Integration with Tech Stacks | Easily integrates with PostgreSQL- compatible applications work with SQL-based data ecosystem | Connects via REST API and gRPC, integrates well with modern machine learning pipelines and tools |
| Data Storage & Indexing | Working with PostgreSQL’s storage and indexing requires vector-specific indexing for optimized queries | Offers built-in, optimized indexing, no need for manual configuration |
| Vector Search Performance | Good performance with smaller datasets may face latency issues with high-dimensional vectors | Optimize high dimensional, large scale vector search, consistently low latency responses |
| Data Consistency | Supports ACID transactions, ensure consistency across queries | The eventual consistency model, suited for real-time search, prioritizes fast response over strong ACID |
| Real-time Updates | Not as efficient, updates on vectors can lead to index rebuilding, impacting performance | Real-time updates with minimal latency, optimized for dynamic, frequently updated datasets |
| Cost | Typically more cost-effective as it utilizes existing PostgreSQL setups, it may have hidden scaling costs | Premium pricing, variable costs based on usage, vector dimensions, and query volume |
| Security | Inherits PostgreSQL’s security features, relies on host setup for further security configurations | Robust security with end-to-end encryption, compliance with major data regulations |
| Community & Support | Supported by PostgreSQL, community, and open-source contributions, documentation may vary in quality | Dedicated support and documentation from Pinecone, extensive resources, and professional assistance |
Cost Considerations for Pgvector vs Pinecone
When considering vector search databases, the battle of Pgvector vs Pinecone is there, and both offer unique benefits and cost structures.
Pgvector is generally cost-effective, particularly for users who generally work with PostgreSQL; it doesn’t require a separate vector database. The main cost depends on its underlying PostgreSQL instance, so users can control expenses by adjusting instance size and storage.
The Pgvector benefits for large-scale, high dimensional vector searches; the Pgvector performance may incur higher operational costs due to the need for additional configuration and potentially significant performance tuning.
Pinecone vector search follows a premium pricing model for high-performance vector search, with costs that scale based on vector storage size, query volume, and index configurations. It is designed to manage service; Pinecone removes the overhead of manual tuning, making it suitable for teams that need scalable vector search without investing heavily in infrastructure maintenance.
While potentially more expensive than open-source solutions, Pinecone’s managed service structure can be cost-effective for large datasets.
When to Choose Pgvector?
Consider using Pgvector when your app needs more storage and similarity search of high-dimensional vector data. It is particularly useful for apps that involve machine learning models, NLP, recommendation systems, and other AI-powered solutions. The seamless Pgvector performance makes it a flexible and scalable choice for vector database needs.
When to Choose Pinecone?
Choose Pinecone when you want to manage a purpose-built vector database that specializes in high-performance, scalable similarity search across large datasets. Pinecone benefits apps with real-time recommendations, semantic search, and personalization with a focus on machine learning embeddings. If a project requires rapid development and low maintenance for vector search, Pinecone workflows come in handy.
Choosing the Right Vector Database for Your AI Applications
To sum up, the debate of Pgvector vs. Pinecone vectors, both offer distinct advantages depending on your project needs and infrastructure. Pgvector is an excellent choice if you are looking to integrate vector storage and similarity search directly into an existing PostgreSQL setup, with a seamless approach and minimal additional infrastructure.
On the other hand, Pinecone provides a fully managed, specialized vector database that excels at scaling high-performance vector search and scaling real-time, mostly suited for ML-intensive applications with large datasets.
At Openxcell, we understand the unique strengths of Pinecone and Pgvector for specific use cases. Our team brings expertise in database optimizations, high-performance ML workflows, and easy integration, ensuring the vector database is set up for maximum scale and efficiency.


Manushi, a former literature student, now crafts content as a writer. Her style merges simple yet profound ideas. Intrigued by literature and technology, she strives to produce content that captivates and stimulates.




