A Step-by-Step RAG Evaluation Process & Key Metrics Explained
- Why is RAG Evaluation Needed?
- Key RAG Evaluation Metrics
- RAG Evaluation Metrics for Retriever Components
- RAG Evaluation Metrics for Generator Components
- RAG Evaluation: A Step-by-Step Process
- Step 1: Testing Framework Creation
- Step 2: Primary Cause Analysis & Testing
- Step 3: Manual Assessment
- Important RAG Evaluation Frameworks One Must Know
- RAGAs
- Vertex AI
- Quotient
- Arize Phoenix
- Final Thoughts on RAG Evaluation
What This Blog is About
Periodic RAG Evaluation is necessary for optimally operating LLM, and this blog will discuss how to do it. First, we will discuss the importance of RAG evaluation, followed by evaluation metrics that one should know about. Lastly, this blog will discuss an easy 3-step process to assess RAG processes and popular evaluation frameworks. The aim is to provide clarity on the otherwise complex RAG evaluation process.
Businesses are investing in RAG evaluation to ensure proper LLM performance. While RAG manages accuracy through its intelligent retrieval and generation capabilities, periodic monitoring and assessment maintain accuracy and optimal performance.
RAG evaluation determines performance accuracy based on pre-determined metrics. It allows businesses to monitor the pipeline’s recall ability and precision.
The blog will discuss everything from key metrics to the assessment process and frameworks. Though, before that, it is important to understand how it is beneficial.
Why is RAG Evaluation Needed?
Regular evaluation prevents LLM hallucination. Inherent biases, fabricated information, and contextually inaccurate information generation are some of the significant concerns when utilizing LLMs. RAG evaluation helps mitigate these issues.
These assessments also help businesses recognize outdated information and gaps to minimize output inaccuracies. RAG evaluation resolves issues related to retrieval, such as lack of precision, poor recall, and irrelevant information retrieval. This allows LLM to perform optimally with both complex and straightforward commands.
Suggested Read: RAG vs Fine-Tuning: Which AI Model Approach is Best?
Key RAG Evaluation Metrics
RAG comprises two components: retriever and generator. Both have separate metrics to determine the effectiveness of RAG evaluation. The retriever indexes and searches relevant information from external sources, and the generator uses the retrieved data to generate contextually relevant output.
RAG evaluation metrics for retriever components assess the quality of the retrieved context, while the one for the generation component evaluates outputs based on the retrieved information.

RAG Evaluation Metrics for Retriever Components
Since the retriever gathers and indexes data from outside sources, getting contextually relevant information is crucial. The evaluation metrics for retrieval components check the same thing: whether the output is contextually relevant and provides sufficient information.
To explain the two in detail,
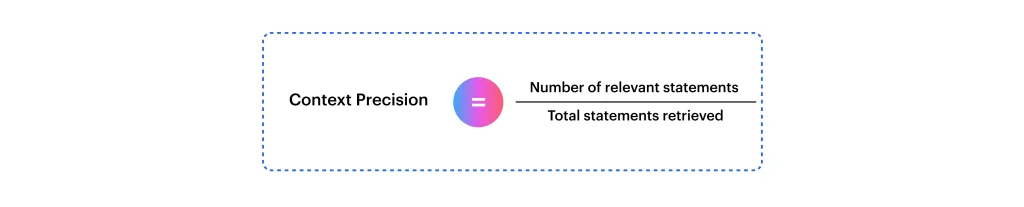
Context Precision
It determines the relevance and truthfulness of retrieved information. This RAG evaluation metric checks the amount of contextually precise information in all the statements. The evaluation framework categorizes retrieved data as relevant and irrelevant and then calculates the final verdict using this formula:
Context Recall This RAG evaluation metric checks the accuracy of retrieved information by comparing it against the standard truth. It analyzes and determines the percentage of accurate answers among all the statements generated. A perfect recall score is obtained when all the results are accurate and related to the query. Mathematical representation of this would be:

RAG Evaluation Metrics for Generator Components
Once the information is retrieved, the generation component uses that information to generate output. An optimally functioning generation component will consistently provide high-quality output.
The following evaluation metrics assess LLM’s output quality in terms of information provided, retrieved context, and final output.
Answer Relevancy
This RAG evaluation metric determines how the actual output relates to the user query. Once the retriever separates the relevant statements from the irrelevant ones, the generator selects the more appropriate statements as an output.
Answer Correctness
This metric assesses whether the generated output is factually correct. The key is to calculate the output’s contextual and factual accuracy. To determine that, a standard response is set and used to analyze whether the outcome meets that standard.
Answer Hallucination
This is one of the essential RAG evaluation metrics, which determines whether the output justifies the user query and covers all the related information. The metric ensures that the user input is not misinterpreted and that all the relevant information is conveyed to the user.
RAG Evaluation: A Step-by-Step Process
A thorough evaluation necessitates a proper systematic approach, and the following steps will help achieve that. These steps identify the issues and resolve them to ensure proper LLM functionality.
Step 1: Testing Framework Creation
Testing the RAG systems requires set metrics as a benchmark against which the LLM is tested. Such rapid testing and interaction require a resilient testing framework. The main elements that define the framework excellence are input quality and the reference dataset.
The test dataset needs a broader range to match the complex real-life use cases. A varied set of queries, like questions and phrases, will ensure thorough testing and accurate results. Next, set up reference data as the point of reference for evaluation and scoring.
This framework can be divided into three phases, namely:
- Reference Question & Answers: A set of predefined queries and reference answers to test the output quality.
- RAG System Processes: The retrieval and generation techniques used by the system that need to be evaluated.
- Output Scoring: Using testing metrics to assess and score the output compared to the reference dataset.
Step 2: Primary Cause Analysis & Testing
To understand the root cause of performance gaps, the two RAG components are isolated and tested to find the problem area. Retrieval accuracy and output context are the key identifiers, and any discrepancies in either would help with primary cause identification and rectification.
Isolated testing narrows down the problem area, accelerating the assessment and modification process. The process goes back and forth between testing and modification until the desired results are achieved.
One thing to keep in mind is to modify and test based on the discrepancies and not rush the task, as it may impact the results. Making measurable changes at every step of analysis is a must to achieve a perfect score on all metrics.
Step 3: Manual Assessment
Once the automated testing is done, humans evaluate the subtle things like response tone, clarity, and ambiguity (if there is). Automated quantitative and manual qualitative analysis gives a more holistic view of RAG performance.
Apart from response tone and accuracy, human evaluation also includes things like UI/UX, system performance, and can evaluate specific system features based on the requirements. Manual assessment takes a lot of time and requires experts for meaningful results.
Related Read: RAG Pipeline: Benefits, Components, and How to Build It
Important RAG Evaluation Frameworks One Must Know
RAGAs
It is an open-source tool that tests factual accuracy, answer relevance, and contextual accuracy regarding the query, among other things. RAGAs also assist developers in generating test data, which further accelerates the process and improves accuracy.
Vertex AI
Vertex AI’s gen AI evaluation services test and compare generative models on custom metrics. It works on Google’s and third-party models and supports model selection, fine-tuning, custom metrics, and more.
Quotient
Quotient AI automates the complete evaluation process by running and assessing RAG pipelines to test for answer faithfulness, relevance, and similarities. It requires evaluation datasets to be used as benchmarks for accurate evaluation and scoring.
Arize Phoenix
It is another open-source tool that improves the RAG performance by backtracking the response-building process. This helps quantify errors and gaps behind bad-quality outputs, LLM hallucinations, etc.
Final Thoughts on RAG Evaluation
RAG evaluation is about understanding the role of the retrieval and generation components and how the two work together to power the LLM solutions. Everything requires meticulous attention, from defining the data benchmarks to determining the output quality.
The evaluation process might seem a bit complicated, but with the right service provider, you can hire experts to upgrade and maintain your digital infrastructure. Openxcell’s expertise in RAG-powered solutions encompasses everything from development to maintenance.
Our experts go above and beyond to ensure client satisfaction. They showcase unmatched expertise in RAG-powered solution development, evaluation, and upgradation. Connect with our team to learn more about our wide range of services and transformative capabilities.


A Philosophy student who knocked on the door of the technology, Vaishnavi is a writer who likes to explore stories, one write-up at a time. A reader at heart, she plays with words to tell the tales of the digital world.





