Vector Database vs Graph Database: A Guide to Choosing the Right Solution
- What is Vector Database
- What is Graph Database?
- Vector Database vs Graph Database: A Tabular Comparison
- Key Similarities Between Vector and Graph Databases
- Vector db vs Graph db: What’s the Difference?
- Graph vs. Vector Database: When to Use Each
- Use Vector Database When:
- Use Graph Database When:
- Final words
When we hear the word “data” in the context of the IT industry, it perplexes us, and it is complex because there are many types of databases. The databases are becoming essential for retrieving and managing unique needs. Two popular options that often compete in the data management landscape are vector databases vs. graph databases, each offering its own unique set of advantages.
Vector databases are designed for similarity searches in high-dimensional data, while graph databases are perfect for mapping relationships. It has sparked an ongoing debate over which database types are suitable for modern work like big data, machine learning, and Gen AI services.
In this blog, we will explain the never-ending debate of vector databases vs graph databases, covering their key features, cons, pros, and ideal use cases. We’ll also provide a quick comparison table to help you decide which database best suits your data needs.
What is Vector Database
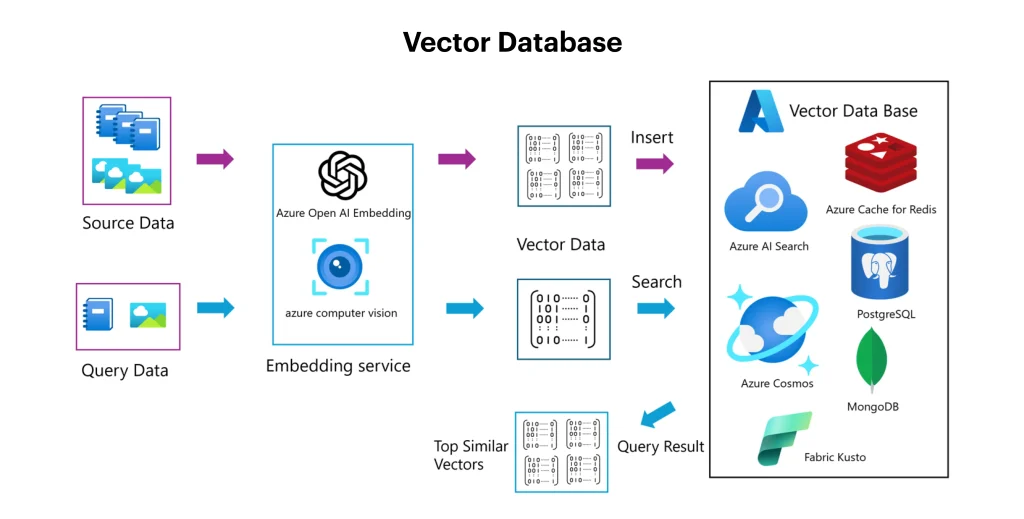
In the comparison of vector vs graph database, the vector is a type of database that is optimized to store and query data in vector format, where data points are represented as numerical vectors. The format allows high-speed similarity searches, which is perfect for AI and machine learning apps, where finding similar data points is crucial. By converting data into embeddings, vector databases enable efficient retrieval of unstructured data like text, audio, and images.
Pros
- High-Performance Similarity Search: Excellent for finding similar data points, crucial in recommendation systems and search engines.
- Scalable and Fast: Handles large volumes of high-dimensional data efficiently and is suitable for real-time applications.
- Integration with ML Pipelines: Easily integrates with machine learning models, organizing data processing for AI applications.
- Efficient for Unstructured Data: Ideal for unstructured data, as it processes numerical embedding rather than traditional fields.
Cons
- Limited Relational Capabilities: Not designed for complex data points, and limits the versatility.
- Specialized Querying: Optimized for similarity search rather than traditional SQL-style queries.
- Higher Storage Requirements: High-dimensional vectors can consume substantial storage space, especially with large datasets.
- Dependency on ML Models: Relies on ML models to create vector embeddings, making data accuracy model dependent.
Use Cases
- Recommendation Engines: Suggest similar products or content based on vector similarity.
- Image and Video Search: Quickly find similar videos or images by comparing feature embeddings.
- Document Search: Enables efficient retrieval of documents with related topics in text-based searches.
- Anomaly Detection: Identifies outliers by comparing data embeddings to a baseline vector.
Challenges
- Data Transformation: Requires a machine learning model to convert raw data into vectors, adding complexity.
- Scalability in High-Dimensional Space: Making and indexing high-dimensional data can be resource-intensive.
- Model Dependence: Changes in ML models necessitate re-indexing or re-transforming data.
- Interoperability: Limited compatibility with other database types can complicate integration.
Bonus Read: Pgvector vs Pinecone: Choosing the Right Vector Database
What is Graph Database?

The graph database is designed to store, manage, and query data structured as nodes and edges, making it the perfect choice for handling complex, interconnected data. In the vector database vs graph database, the structure of the graph enables efficient traversal of relationships, allowing for analysis of data connections, often used in social networks, knowledge graphs, and recommendation engines.
Pros
- Excellent for Relationship- Driven Queries: Optimized to quickly retrieve and analyze data based on complex relationships.
- Flexible Data Model: Allows schema-less data structures, making them adaptable for evolving data models.
- Efficient Traversals: It supports fast, multi-hop traversals and is ideal for applications like social network analysis.
- Real-Time Processing: Capable of real-time querying for dynamic, relationship-heavy applications, such as fraud detection.
Cons
- Limited to Relationship-Oriented Data: Not optimized for use cases that require similarity search or high dimensional data processing.
- Scaling Challenges: As graph size and complexity grow, performance can degrade, particularly for deep traversals.
- Steeper Learning Curve: Requires familiarity with graph theory and specialized query languages like Gremlin or Cypher.
- Performance Overhead: Traversals, especially on large graphs, can be resource-intensive.
Use Cases
- Social Networks: Stores user interactions and relationships and enables features like friend suggestions.
- Recommendation Systems: Provides recommendations based on shared interests and user relationships.
- Fraud Detection: It detects fraud patterns by analyzing connections between entities.
- Knowledge Graphs: Manages and queries interconnected data, making it useful for semantic search and AI applications.
Challenges
- Complexity with Large Datasets: Managing large, complex graphs can strain resources and degrade performance.
- Limited Integration with ML Pipelines: It is not widely integrated with machine learning processes as vector databases.
- Data Model Complexity: Requires careful design of nodes and relationships to maintain efficiency, highlighting the importance of following best practices for data modeling to optimize performance and scalability.
- Store Management: Relationships consume storage and may increase redundancy, adding to storage costs.
Vector Database vs Graph Database: A Tabular Comparison
Both vector and graph are specialized databases that handle particular types of data structures and use cases. As both are used to manage and query complex data, it also caters to different needs. So here we will give a tabular understanding of the distinction between vector databases vs graph databases for choosing the right tool for your specific data requirements.
| Feature | Vector Database | Graph Database |
| Data Structure | Multi-dimensional vectors with dense, high-dimensional data embeddings | Nodes, edges, and properties (graph-based) |
| Primary Use Case | Similarity search, recommendations, and semantic search | Relationship-based queries, social networks, and fraud detection |
| Ideal For | Applications involving unstructured data like images, audio, and text | Complex relationships and connected data like knowledge graphs and social graph |
| Query Types | K- NN search, dot product, and cosine similarity | Traversals, pathfinding, and pattern matching |
| Scaling | Horizontal scaling with distributed vector indexing | Vertical and horizontal scaling with replication and sharding |
| ML Integration | Design to store embeddings from ML models and enable fast similarity search | It can be used to build features for ML models but not for embedding storage |
| Examples | Milvus, Pinecone, FAISS, and Weaviate | Neo4j, ArangoDB, TigerGraph, Amazon Neptune |
Key Similarities Between Vector and Graph Databases
- Both Store Complex Data
In conversation of graph vs vector database, both are designed to handle complex, non-tabular data structures. Vector databases manage high-dimensional embedding, and graph databases manage intricate relationships between entities.
- Optimize for Specialized Queries
Both types of databases are optimized for particular types of queries that traditional databases struggle with. Vector databases excel in similarity search, allowing fast identification of nearest neighbors in pixel-dimensional space. Graph databases optimize traversal queries and enable efficient exploration of connections.
- Use in AI and ML Applications
Vector and Graph databases play a crucial role in AI and ML applications. Vector databases are often used to store embeddings from ML models, supporting tasks like recommendation systems and semantic search. Graph databases enhance AI-driven apps by modeling complex relationships, where Knowledge graph construction and detecting patterns in connected data.
Vector db vs Graph db: What’s the Difference?
- Data Structure
Vector Databases use multi-dimensional vectors to represent data points, where each Vector is an embedding capturing the semantic meaning of input. In contrast, Graph Databases structure data as entities and relationships focusing on traversing and capturing the data elements.
- Query Focus
Regarding graph database vs vector database, the Vector optimizes for similarity-based queries like KNN searches, which find the closest vectors in strong dimensional space. Graph databases focus on relationship-driven queries and pattern matching to explore the interconnectedness of data points.
- Scalability Constraints
Vector Databases face challenges in scaling as the dimensionality of vectors increases, often requiring distributed indexing to maintain the performance. Graph databases might encounter scalability issues when dealing with dense or highly connected graphs, with several relationships impacting query performance.
- Learning Curve
Vector Databases typically have a simple learning curve for users familiar with vector mathematics and similarity search concepts. Graph databases can be more complex to learn due to their unique data modeling and query languages, and they require a deep understanding of graph theory and traversal techniques.
Graph vs. Vector Database: When to Use Each
The comparison between vector database vs graph database depends on the specific use case and nature of the data. Each database type offers unique advantages tailored to different problem-solving scenes in data management.
Use Vector Database When:
Vector databases are perfect for handling complex, high-dimensional data like text embedding, user preferences, and images. They excel at similarity searches, making them perfect for apps such as NLP, recommendation systems, and computer vision. If one’s goal is to perform accurate and fast searches in large datasets based on similar metrics, a vector database is the right choice.
Use Graph Database When:
Graph databases are designed to capture relationships and interconnected data points. They are well suited for use cases that involve social networks, supply chain management, fraud detection, and knowledge graphs. If your focus is on exploring connections and traversing complex networks of data or patterns, a database provides the framework for querying and analysis.
Final words
In conclusion, graph databases and vector databases serve different purposes based on the type of data and analytics needs of applications. Graph databases excel at querying and managing complex relationships between interconnected data points, while vector databases are optimized for high-dimensional similarity searches, making them perfect for tasks like NLP and recommendation engines.
At Openxcell, we specialize in working with graph databases and vector databases to deliver optimized data solutions catering to business needs. Whether you need to uncover hidden relationships in data or build advanced AI-driven applications, our data analytics services provide end-to-end support.


Manushi, a former literature student, now crafts content as a writer. Her style merges simple yet profound ideas. Intrigued by literature and technology, she strives to produce content that captivates and stimulates.




