Multimodal AI: Unlocking the Future of Intelligent Systems
- What is Multimodal AI?
- Multimodal AI vs Unimodal AI
- Benefits of Multimodal AI
- 1. Enhanced Contextual Understanding
- 2. High Accuracy Results
- 3. Intuitive User Experience
- 4. Versatility Across Domains
- 5. Better Adaptability & Flexibility
- Challenges & Risks of Multimodal AI
- 1. Requires Extensive Data
- 2. High Computation Requirements
- 3. Aligning Huge Amount of Data
- 4. Ethical Concerns
- 5. Bias in AI models
- How Does Multimodal AI Work?
- Top Real-life Use Cases of Multimodal AI
- 1. Healthcare: Improving Diagnostics
- 2. Automotive: Self-driving Cars
- 3. eCommerce: Offering Tailor-made Shopping experiences
- 4. Education: Personalized Learning
- 5. Finance: Risk Assessment
- Best Multimodal AI Examples
- Final Thoughts on Multimodal AI
- Frequently Asked Questions
Going back to 20 years, who thought there would be a technology that could not only see text or listen to audio but also provide output? That’s the power of artificial intelligence.
But now, multimodal AI, the frontier of generative AI, understands multi-sensory inputs and provides you output in text, audio, image, video, etc. Simply put, it feels like you are interacting with a real human being for your daily tasks.
The discussion of multimodal AI started with the launch of GPT-4, the first to provide output in text and images, followed by GPT-4V, which provides hyper-realistic interactions.
Since then, the demand for multimodal AI has grown across industries. According to MarketsandMarkets, the market size of multimodal AI was $1 billion in 2023, and it is expected to reach $4.5 billion in 2028.
So, whether you are a business owner, data scientist, AI-ML engineer, product manager, or an AI enthusiast and want to consider Generative AI development for your next project, you should be aware of multimodal AI.
To eliminate guesswork, we have crafted a detailed guide on multimodal AI. Here, we will discuss the basics of multimodal AI, its benefits and challenges, real-life use cases, and examples.
So, let’s dive in.
What is Multimodal AI?
Multimodal AI is better known as an artificial intelligence system that takes input in multiple forms of data, such as text, video, and images, makes future predictions, and generates output. In terms of machine learning, modality is referred to as a type of data.
By leveraging different forms of modality, multimodal AI can deliver richer insights and better interactions. For example, multimodal AI is beneficial for writing program code, analyzing text from a photo, understanding things from audio, and providing output in different formats as needed.
Multimodal AI vs Unimodal AI
When comparing multimodal AI vs. unimodal AI, the primary difference lies in how they handle the data. Unimodal AI is a type of generative AI system that can handle only one type of data at a time, such as text or data. For instance, ChatGPT 3.5, currently the free version of ChatGPT, can only take input in text and provide output in the same modality.
On the contrary, multimodal AI possesses the power to take input in different modalities, such as text and image, and provide the output in the same manner. Again, a famous example would be ChatGPT 4, the upgraded version of ChatGPT.
Benefits of Multimodal AI
1. Enhanced Contextual Understanding
As discussed earlier, multimodal AI has the potential to interpret data of different types. This model obtains an in-depth contextual understanding of any topic, which is not possible in a single modality.
In simple words, multimodal AI obtains the sense of a phrase or a word by considering the surrounding concepts or texts. It is able to achieve this by leveraging natural language processing (NLP), a field of AI that interprets, manipulates, and comprehends human language.
For instance, if you prompt a multimodal AI to generate a video of a hill station, it would consider what it looks like, what kind of activities happen there, weather conditions, and more.
2. High Accuracy Results
Multimodal AI combines massive data from different sources, such as text, video, and images, reducing errors and achieving more accurate & reliable results. Simply, multimodal AI leverages the complementary information available in different modalities to deliver precise output.
This type of model is beneficial in tasks such as image captioning, where you are required to generate a precise and accurate description of an image. It is also great for obtaining reliable output by considering a speaker’s facial expressions and speech recognition.
3. Intuitive User Experience
The model encourages a highly intuitive user experience by enabling users to interact in the way they like. Users can interact naturally with the AI via different methods, such as text, audio, images, and video, which makes the technology more accessible.
By providing such adaptability, multimodal AI works according to individual preferences and takes user satisfaction to a new level by allowing them to communicate in their desired manner.
A simple yet effective example here would be recipe generation. Rather than describing an entire list of things available in a fridge, a user can take a picture and upload it in AI to get a suitable recipe.
4. Versatility Across Domains
This technology benefits a wide range of industries, including web development, academic research, content creation, eCommerce, entertainment, and more.
For instance, in the education sector, it can generate content with rich text, images, and videos as required. Another example can be content creation; it can help you generate an entire social media post with text, images, and hashtags.
5. Better Adaptability & Flexibility
All multimodal AI systems are highly adaptable; they adjust to new tasks or data types whenever needed. Due to this flexibility, this technology evolves with changing environments, user preferences, task requirements, and ongoing market trends.
For instance, in marketing, this technology can help businesses evaluate customer feedback in different formats, such as text reviews, video reviews, and social media posts on different platforms. Further, companies can modify the product or service to satisfy customer needs and refine their marketing strategy to reach a wider audience.
Challenges & Risks of Multimodal AI
1. Requires Extensive Data
As we all know, multimodal AI works with different types of modalities. Hence, these models require a large amount of data in multiple modalities, such as text, audio, video, and images, to function as needed. However, collecting this enormous data will consume a lot of time and effort.
For instance, building an AI that generates user–friendly and engaging videos in different languages will require a massive amount of video content and scripts. Another example is building an AI tool that can convert text to images or vice versa, which will require massive text and a database of pictures.
Without enough data, the model will not perform as required, resulting in poor outputs.
2. High Computation Requirements
Multimodality or multimodal AI is now mainstream in businesses because of the massive amount of known or unknown data available at their disposal.
This model can process and analyze petabytes of diverse data from different modalities simultaneously, thus requiring massive computational power to function at the optimal level. Further, this results in huge water and carbon usage.
Besides this, the model requires robust hardware infrastructure and effective algorithms to ensure it provides different types of output according to the users’ requirements.
For example, effectively training a Dall-E model to generate attractive and reliable images will take a few weeks or months, the latest GPUs, manpower, and other resources; all of this might not be possible for a team with constrained resources for multimodal AI development.
3. Aligning Huge Amount of Data
Aligning immense data is a crucial challenge in multimodal AI. Why? The data comes in different modalities: text, images, videos, and more. Secondly, the data is available in different sizes, scales, semantics, and structures. Misaligning this data can result in false interpretations and wrong outputs.
For instance, if you have trained a model with a detailed amount of text information but low-quality images, this kind of difference may affect the AI, and it can’t interpret and analyze the data well. Hence, output is also affected.
Another example: If timestamps and textual annotations are not inserted at the right places in a video or audio, it may be challenging to process the applications made for video summarization or speech recognition.
4. Ethical Concerns
Multimodal AI systems have privacy issues. These systems collect a massive amount of sensitive personal information from users, such as their facial expressions, voice recordings, eye movements, texts, and more. As these systems collect data, it is essential to prevent data misuse and maintain trust.
The data collection method of an AI model can also lead to ethical concerns. Many AI systems collect public or private information of a particular set of users and store data without their consent. This vast amount of data collection causes data transparency and accountability. Implementing some of the best security practices for protecting users’ sensitive data is the need of an hour as it comprises extensive insights.
For instance, a smart home speaker may collect private conversations with you and others at your home. To ensure this doesn’t happen, building a multimodal AI that can function according to users’ needs while maintaining their privacy is necessary.
5. Bias in AI models
Multimodal AI often makes biased decisions based on the existing data fed into their system. Bias in multimodal AI usually results in unfair discriminatory outcomes, where specific types of people are often overlooked or misinterpreted.
For instance, AI trained with images of people of a specific age, gender, and race in a region might not detect individuals from different backgrounds.
Resolving these issues of biases is crucial for building highly equitable AI systems. It starts with arranging the training datasets appropriately and doing in-depth testing of the existing outcomes until they deliver entirely fair outcomes.
How Does Multimodal AI Work?
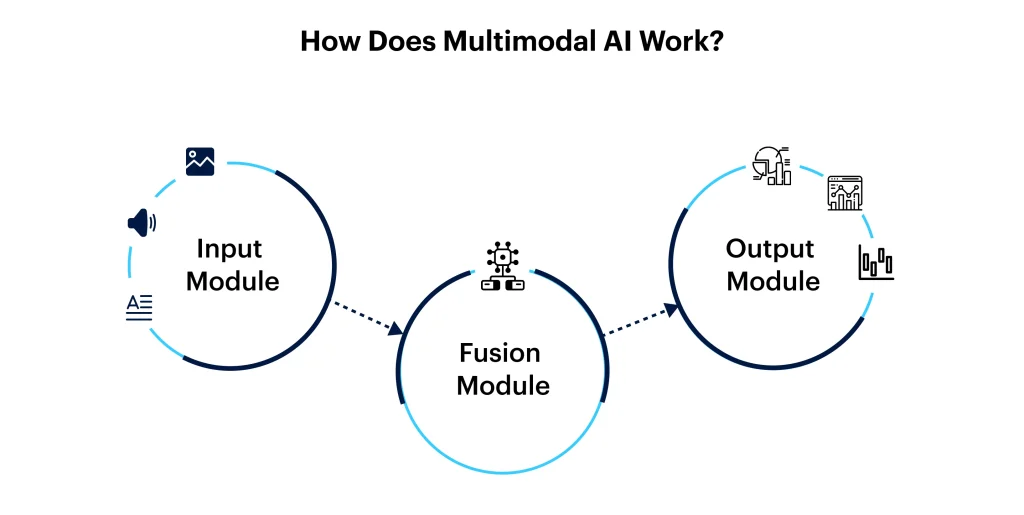
As mentioned before, multimodal AI models function by blending different data sources, such as text, video, and audio. This technology becomes familiar with anything by collecting information from different sensory channels, and then helps in decision-making.
This model comprises three main components: the input module, the fusion module, and the output module. Let’s understand these modules in detail.
Input Module: This module comprises different unimodal encoders, referred to as the AI’s sensory system. The model collects and processes different data modalities: text, audio, video, and images. It leverages unique algorithms to fetch all the essential data from every modality. For instance, it might utilize computer vision techniques to process text, natural language processing for text, and a speech recognition algorithm for audio.
Fusion Module: The fusion module draws features and characteristics from every modality, combines them, and forms a single presentation. The AI utilizes best-in-class techniques, such as mechanisms, concatenation, and interactions between multiple models to determine the correlations and patterns among various modalities. Further, the model uses this data to make more refined and futuristic outputs.
Output Module: The output module is referred to as the classifier. It generates relevant final responses or content depending on the fused data. The AI can interpret all the data to offer more contextual output in text, image, audio, or video. The primary purpose of this module is to ensure that the model effectively communicates the insights and generates creative output based on the user’s needs.
Top Real-life Use Cases of Multimodal AI
Some industries have understood the importance of AI and have started implementing it in their daily tasks. Here are several compelling real-life use cases of multimodal AI.
1. Healthcare: Improving Diagnostics
The healthcare industry is always at the forefront of adopting new technologies and trends. This industry has adopted AI before various other sectors. According to the latest report, the AI market size in healthcare was $19.54 billion in 2023, and it is expected to reach $27.69 billion in 2024 to $490.96 billion in 2034.
Currently, multimodal AI can analyze different images, such as X-rays and CT scans. The model also considers symptoms, clinical history, patient data, and more to help medical professionals understand the condition and make more accurate diagnoses.
Also Read: AI in Healthcare
2. Automotive: Self-driving Cars
In the automotive sector, businesses can leverage multimodal AI extensively in self-driving technology. Combining these technologies helps integrate data from multiple sources, such as cameras, LiDAR, Radar, and GPS. The data includes the vehicle’s environment, nearby objects and their speed, distances between two objects, and location and navigation.
For instance, self-driving cars can be trained well with AI to identify visual cues, navigate through traffic quickly, spot upcoming obstacles, and make effective decisions regarding driving. Ultimately, using multimodal AI in self-driving cars helps enhance convenience, safety, and the overall driving experience.
3. eCommerce: Offering Tailor-made Shopping experiences
AI in eCommerce is not something new. Various popular online stores have implemented it long ago. However, the introduction of multimodal AI will transform the entire eCommerce industry. This new model allows online stores to examine browsing history, buying patterns, and social media activity to offer personalized product recommendations or targeted advertising accordingly.
Now, think that you are browsing in an online store and observe that it presents you with shoes of your size and home decor that adjusts well to your environment. The multimodal AI is able to offer accurate results by considering your data, textual browsing history, and overall behavior while surfing the internet. It helps you satisfy the needs of your customers, build trust and loyalty, and improve engagement and, ultimately, the shopping experience.

4. Education: Personalized Learning
Multimodal AI in education can help understand the student’s learning style, pace, and format (text, video, and audio) and then craft dynamic learning materials according to their needs. The primary purpose of implementing this model is to provide a personalized learning experience to the user, thereby increasing their comprehension and retention.
For instance, consider that there is an AI system that adjusts the learning material and the teaching style based on real-time expressions, tone of voice, and answers to questions. A great example here would be the Ultimate Guitar app. This app has transformed how users practice and learn guitar.
5. Finance: Risk Assessment
In the financial sector, multimodal AI is responsible for improving institutions’ risk assessment processes and decision-making capabilities.
In the first instance, it integrates and processes traditional financial data, including market trends, economic performance, and customer behavior. It also considers other data, such as social media sentiment, news reports, and satellite news, to a refined view of the financial landscape.
For instance, at the time of the loan application, an AI-based system reviews your credit score and analyzes your social media activity to identify any signs of financial stability.
Also Read: AI in Banking – How Artificial Intelligence is Used in Banks
Best Multimodal AI Examples
Here are some of the most popular multimodal AI examples available in the market right now.
- GPT-4o: GPT-4o is built by OpenAI and is a cutting-edge AI with all the features & functionalities of ChatGPT-4, one of the best chatbots in the market. This model can handle text, audio, and video. It is highly recommended for applications that deal with content creation, education, and customer support.
- Claude 3: It is yet another multimodal AI developed by Anthropic. The model can process and analyze text and images. It is excellent at describing visual content, answering questions from the visual content, comparing visual content, and generating textual content.
- Gemini: Gemini by Google is a robust multimodal AI that interprets and processes text, images, and video inputs. The model becomes familiar with content fetched from different modalities, improving search, content creation, and interactive experiences.
- Dall-E3: Dall-E3 is also a multimodal AI developed by OpenAI. It is also one of the most popular AI image generators available in the market. It can generate highly accurate images from textual descriptions.
- CLIP: CLIP stands for Contrastive Language-Image Pre-Training, which was also developed by OpenAI. This model easily understands images and text. It is extensively trained on massive datasets of images and descriptions; hence, it can efficiently perform tasks such as zero-short classification and image search.
Final Thoughts on Multimodal AI
Multimodal AI is here to bridge the gap between humans and machines. This new technology will move towards the development of more intelligent and content-aware systems that have the capabilities to interpret, process, and respond to a diverse range of modalities. With the evolution of this model, there will be significant improvements in emotion recognition, cross-model learning, and the ability to respond like humans.
Moreover, many industries will likely adopt this model to streamline their operations, offer next-generation experiences to customers, and grow their businesses.
If you also want to implement multimodal AI for your business, contact us today. OpenXcell provides AI software development solutions for various industries worldwide. Our AI development team understands your needs and utilizes the most suitable technologies and tools to deliver a robust AI solution.
Frequently Asked Questions
1. How is multimodal used in Generative AI?
Generative AI makes the most of multimodal capabilities to create content of different modalities or data types. For instance, it can generate nuanced text besides relevant images or video content that is compatible with the audio and visual elements. This dynamic method is excellent for rich storytelling and highly intriguing experiences across different fields such as advertising, marketing, gaming, virtual reality, etc.
2. Is ChatGPT a multimodal?
The most recent versions of ChatGPT, including ChatGPT-4V and ChatGPT-4o, are built with best-in-class multimodal capabilities. These models can process input and output data in text, audio, and video, so we can say ChatGPT is multimodal.
3. How do multimodal AI models handle various types of input?
Here is how multimodal AI models handle a wide range of inputs.
- Text to Image Generation and Description: Several well-known image generators, such as OpenAI’s CLIP and Dall-E, can produce images from textual descriptions. They respond like this because they are trained on many datasets.
- Visual Question Answering: Popular models such as VisualBERT and ViLBERT can generate open-ended questions based on an image and respond effectively. These models mix visual data with textual queries, giving them the opportunity to understand the context of images and answer accordingly.
- Image-to-Text Search and Text-to-Image: OpenAI’s CLIP model interconnects images with their textual descriptions. Whenever a user provides text, the model understands the context and responds with the most suitable images. Conversely, it can give text from an image.
- Video-Language Modeling: Several models are available in the market that can identify the frames and linked language to gain a deeper understanding of the context. These are highly suitable for applications that need video captioning and content summarization.


Girish is an engineer at heart and a wordsmith by craft. He believes in the power of well-crafted content that educates, inspires, and empowers action. With his innate passion for technology, he loves simplifying complex concepts into digestible pieces, making the digital world accessible to everyone.




